
|

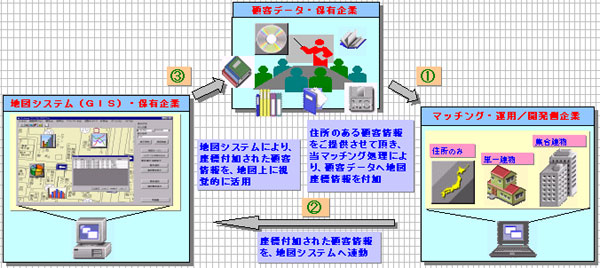
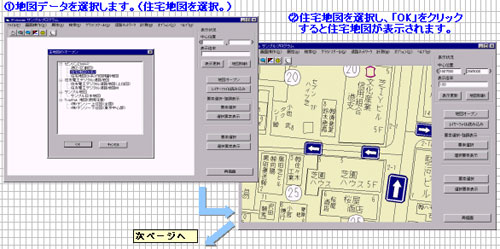
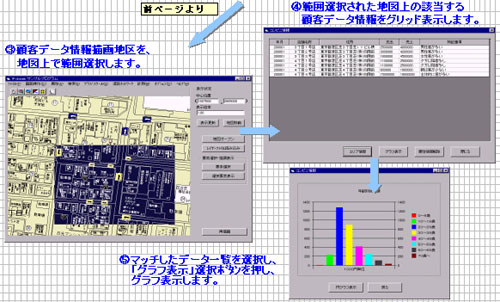
●弊社のマッチング処理により、顧客データへ地図の座標情報を付加します。
座標付加された顧客データを、地図システムにより視覚的に地図上に展開する
ことにより、顧客の営業戦略、業務拡大手段としての活用が図れます。
|

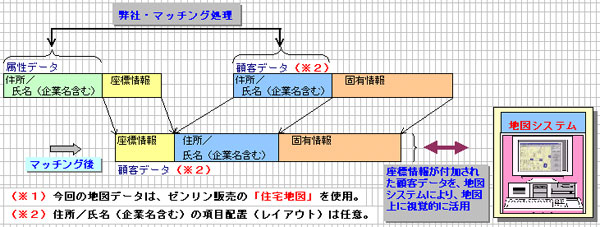
●顧客データの住所/氏名(企業名含む)と地図データ(※1)の住所情報データ
(以降属性データ)の住所/氏名(企業名含む)をマッチングさせます。マッチ
した属性データの座標情報を、顧客デーータの座標情報を、顧客データへ追加
します。
●顧客データへ追加された座標情報をもとに、地図システム(オプションのシステム)
により、地図データの座標情報とリンクさせます。顧客データの固有情報を地図上
に視覚的に展開することにより、最大限の活用を図ります。
|


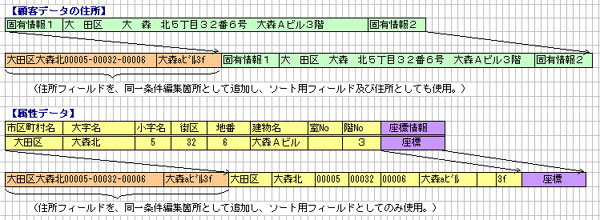
●住所のマッチングを行うには、「シーケンシャル・ファイル化方式」の為、住所
が昇順にソートされていなければなりません。
住所のソートを実現する方法としては、顧客データと属性データの 先頭部分に
各々住所フィールドを追加し、下記「編集基準」のように加工を行い実現して
おります。
『編集基準』
・市区町村名、大字名のスペース・カット
・小字、街区、地番の5桁編集及び半角ハイフン連結
・数字、カタカナの半角変換、英字の小文字変換
・建物名以降を地番と分離し、シフト
|

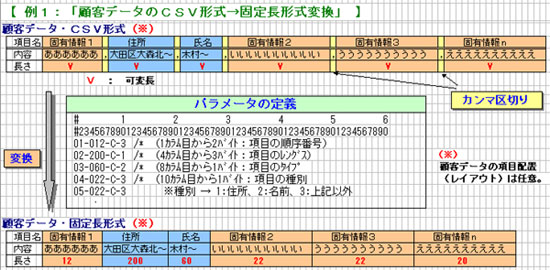
●「外部パラメータ方式による柔軟仕様の実現」として、各種の外部パラメータ
を定義することにより、アプリケーションの変更を最小限に押さえることで
実現しております。
固定長フォーマットで提供される場合は、そのまま使用します。
『外部パラメータ方式』
・【 例1:「顧客データのCSV形式→固定長形式変換」 】
・【 例2:「漢字住所・大字名の「カタカナ」→「ひらがな」変換用パラメータ定義」 】
・【 例3:「カタカナ住所・選択変換用パラメータ定義」 】
・【 例4:「ソート用パラメータ定義」 】


|

●「マッチング率を最大限に向上させる方策」として、顧客データと地図・属性
データの住所/氏名が同一編集基準のもとに、事前変換を行うことにより実現
しております。
『マッチング率を最大限に向上させる方策』
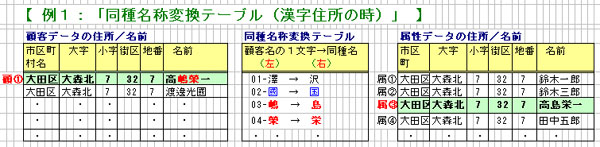
・【 例1:「同種名称変換テーブル(漢字住所の時)」 】
・【 例2:町名のカタカナをひらがな変換テーブル(漢字住所の時) 】
・【 例3:短縮変換/部分変換テーブル 】
・【 例4:都道府県名カット 】
・【 例5:市区町村、大字、小字、街区、地番の間にスペース・カット 】
・【 例6:つなぎ文字の多種類パターンを全て、半角ハイフン("-")に変換 】
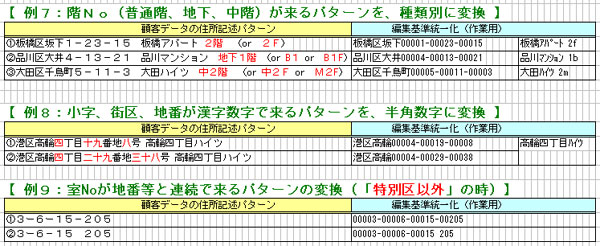
・【 例7:階No(普通階、地下、中階)が来るパターンを、種類別に変換 】
・【 例8:小字、街区、地番が漢字数字で来るパターンを、半角数字に変換 】
・【 例9:室Noが地番等と連続で来るパターンの変換(「特別区以外」の時)】
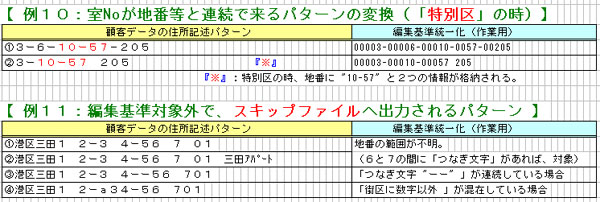
・【 例10:室Noが地番等と連続で来るパターンの変換(「特別区」の時)】
・【 例11:編集基準対象外で、スキップファイルへ出力されるパターン 】
|
【 同種名称による氏名マッチングの処理順序 】
1.1 顧客データ「顧①」の場合
(1) 「同種名称テーブル」の「左の欄(冨澤國嶋邊邉榮)」と「右の欄
(富沢国島辺栄)」を全て取得します。
(2) 顧客データの名前の1文字ずつ(”高”、”嶋”、”榮”、”一”)
をもとに、上記「左の欄」をサーチします。
(3) ヒットした”嶋”と”榮”に対応する文字を右の欄(”島”と”栄”)
から取得し、「顧①」の名前「高嶋榮一」を「高島栄一」へ
置き換えます。
(4) 置き換えた名前「高島栄一」で、再度属性データ(※)の名前と
氏名マッチングを行います。
(※):属性データの名前は事前に「同種名称テーブル」
により変換済み。


|

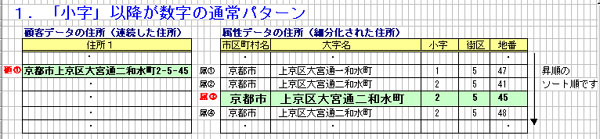
●顧客データの住所は下記「顧①」のように、一般的に連続した形で提供され
ます。連続した住所を「市区町村名」、「大字名」、「小字名」、「街区」、
「地番」とそれぞれ細分化するのは、顧客データのみでは精度がかなり
落ちてしまいます。
住所の細分化精度を高度なものにする為、属性データを用いて行います。
【 細分化の処理順序 】
|
1.1 「市区町村名」の細分化
(1) 属性データの市区町村名「京都市」の内容と、3文字分の文字数
「3」を取得します。
(2) 上記文字数「3」より、顧客データの先頭3文字分「京都市」を
取得します。
(3) 上記(1)属性データと(2)顧客データに対して、「市区町村名」の
テキストタイプ比較を行います。
(a) 一致した時 → 「市区町村名」の細分化決定後、次ページ
の(4)以降を行います。
(b) 一致しない時 → 次の属性データをチェックする為、上記(1)
以降を行います。
|
1.2 「大字名」の細分化
(4) 前ページの一致した属性データの「市区町村名」に「大字名」を
連結し、大字名までの内容と文字数「13」を取得します。
(5) 上記文字数「13」より、顧客データの先頭13文字分「京都市
上京区大宮通二和水町」を取得します。
(6) 上記(4)属性データと(5)顧客データに対して、「市区町村名+大字名」
のテキストタイプ比較を行います。
(a) 一致した時 → 「大字名」の細分化決定後、下記(7)「小字」
以降の細分化を行います。
(b) 一致しない時 → 次の属性データをチェックする為、上記(4)
以降を行います。
1.3 「小字」の細分化
(7) 属性データ(「大字名」まで一致の 属②)の「小字、街区、地番」
情報の有無を取得します。
(小字、街区、地番とも「有り」を取得。また、ニューメリック・
チェック記述は省略。)
(8) 顧客データの「大字名」以降、最初のハイフン("-")までの数字
("2")を取得します。
(9) 顧客データと属性データの「小字」のテキストタイプ比較を行い
ます。
(a) 一致した時 → 「小字」の細分化決定後、下記(10)「街区」
以降の細分化を行います。
(b) 一致しない時 → 次の属性データをチェックする為、上記(9)
以降を行います。
1.4 「街区」、「地番」の細分化
(10) 顧客データの「小字」以降、ハイフン("-")と数字を1文字ずつ
チェックしながら
「小字」と同様の方式で細分化します。(「属③」より取得。)
|

●前ページで述べましたように、細分化された顧客データの住所と、細分化
固定長変換した属性データを、各フィールド単位のマッチングを行います。
マッチングには、「住所と氏名(個人名 or 企業名)」及び
「住所のみ」があり、住所については、一戸建て及びマンション、
団地、ビル等 集合住宅を含みます。
【 マッチングの処理順序 】
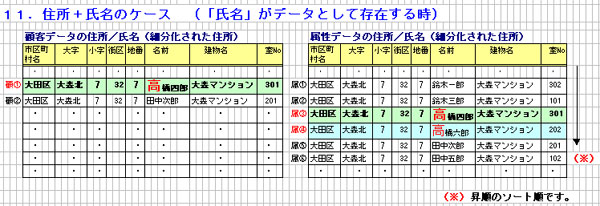
(1) 顧客データの「住所/氏名パターン」を取得します。上記「顧①」の
パターンは「階No以外」全て存在するパターンが取得されます。
(「住所/氏名パターン」の詳細については、下記項番「3.」を
参照下さい。)
(2) 顧客データの住所/氏名パターンをもとに、属性データの地番まで一致
する箇所まで読み飛ばしていきます。
(3) 顧客データの地番まで一致する属性データを、全てスタックテーブルへ
取得します。
(4) 更に、名前の先頭1文字(高橋四郎の「高」)と一致するデータを、
前記スタックテーブルよりチェックテーブルへ取得します。
(「属③」、「属④」がチェックテーブルへ取得されます。)
(5) チェックテーブルの中から、顧客データと一致するフィールドが多い
データの 座標情報を取得します。(「属③」より取得。)
|
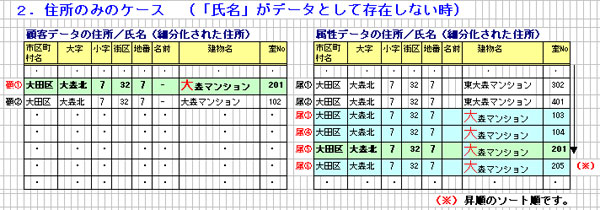
(1) 顧客データの「住所/氏名パターン」を取得します。上記パターンは
「名前、階No以外」全て存在するパターンが取得されます。
(「住所/氏名パターン」の詳細については、下記項番「3.~」を
参照下さい。)
(2) 顧客データの住所/氏名パターンをもとに、属性データの地番まで一致
する箇所まで読み飛ばしていきます。
(3) 顧客データの地番まで一致する属性データを、全てスタックテーブル
へ取得します。
(4) 更に、「建物」の先頭1文字(大森マンションの「大」)と一致する
データを、前記 スタックテーブルよりチェックテーブルへ取得します。
(「属③」、「属④」、「属⑤」、「属⑥」が
チェックテーブルへ取得されます。)
(5) チェックテーブルの中から、顧客データと一致するフィールドが多い
データの 座標情報を取得します。(「属⑤」より取得。)
(※)昇順ソートの順位は、地番までが第1位、名前が第2位、
建物以降が第3位となっています。
|
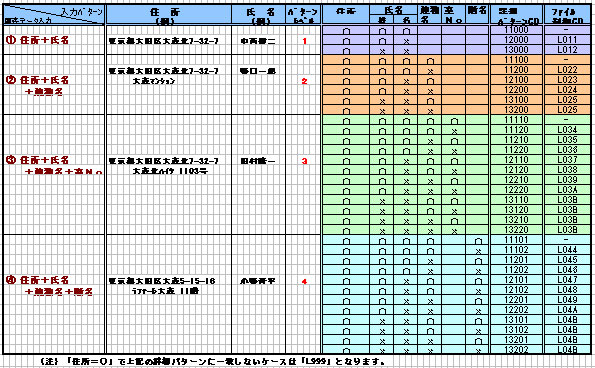
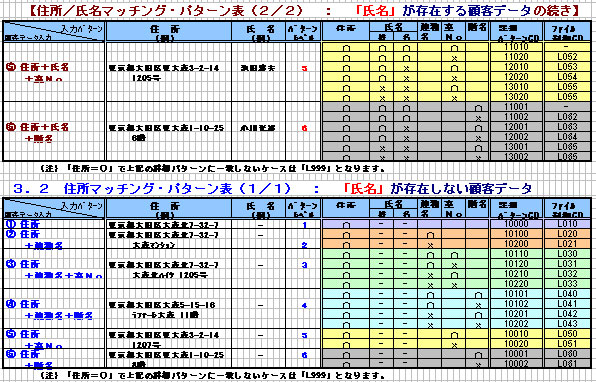
3.「住所/氏名」 or 「住所」マッチング・パターンの考え方
前ページで述べましたように、「住所/氏名マッチング・パターン表」により、
マッチングレベルを決定します。
また、「詳細パターンCD」を参照することにより、マッチングレベル結果の
確認ができます。「ファイル制御CD」については、当コードを使用すること
により、マッチファイル、アンマッチファイルの選択が可能となります。
3.1 住所/氏名マッチング・パターン表(1/2) : 「氏名」が存在する顧客データ
|

●アンマッチになったデータは、どの箇所でアンマッチになったかを特定する
ことが第一に重要となります。
次に、アンマッチになった顧客データと関係がある属性データの関連
データの調査が必要となります。
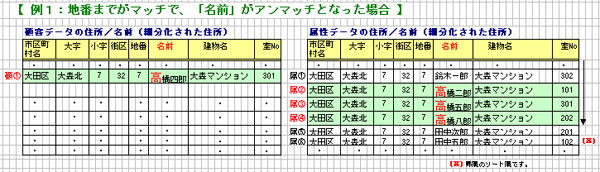
→顧客データの 「地番まで」と「名前の先頭1文字まで」が一致したデータを
もとに顧客データ及び属性データを、それぞれ確認用ファイルとして出力します。
(顧客データに対する属性データの「データ出力番号」は、同一番号を出力。)

|
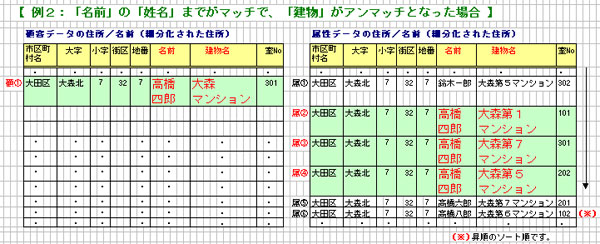
→顧客データの 「地番まで」と「名前の姓名まで」が一致したデータをもとに
顧客データ及び属性データを、それぞれ確認用ファイルとして出力します。
(顧客データに対する属性データの「データ出力番号」は、同一番号を出力。)
|

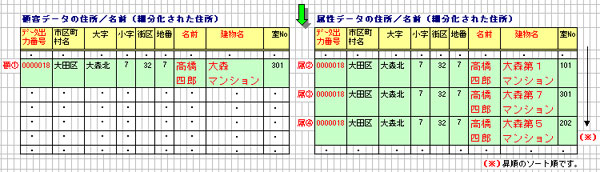
●アンマッチになったデータを整備する場合、顧客データと属性データの「住所
と氏名」だけの関連する情報が必要となります。
検証をよりすばやく行う為、「住所と氏名」だけのアンマッチリスト及び
アンマッチリストファイルを提供しています。
【 例1:地番までがマッチで、「名前」がアンマッチとなった場合 】
→顧客データの 「地番まで」と「名前の先頭1文字まで」が一致したデータ
をもとに作成された下記2つの確認用ファイルがあります。
下記2つの確認用ファイルをもとに、アンマッチリスト及びアンマッチ
リストファイルを作成します。
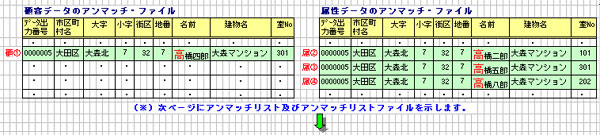
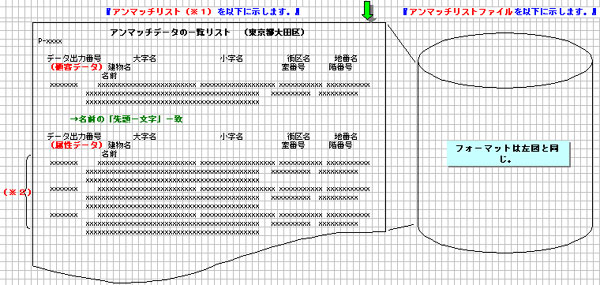
(※1) アンマッチリストについては、シーケンシャル・ファイルとMDBの
2種類の帳票出力を提供しています。
MDBの場合、印刷前のプレビュー機能がある為、アンマッチリスト
ファイルの出力は行いません。
(※2) 「地番まで一致」と「名前の先頭1文字まで一致」の 属性データを
全て出力します。
|

●従来の処理方式は、データ検索の容易性、アプリケーション作成容易性から、
属性データの「DB化」処理を行っていたが、5万件、10万件、50万件
と大量データ処理時の処理時間の延びが膨大になり、改善策として
「シーケンシャル・ファイル化(※)」により、大量データ処理を実現
しています。
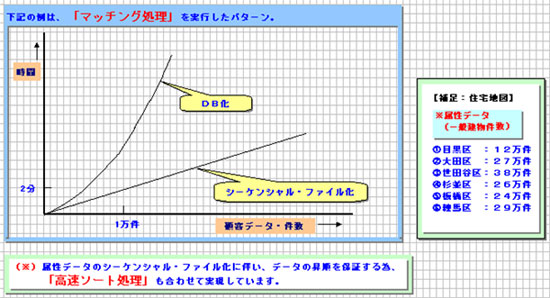
|

●「属性データの抽出/固定長変換/加工/名称付加処理」、「顧客データの
抽出/加工/細分化/マッチング処理/MDB作成」の 自動運転処理を行う。
自動運転監視アプリにより、「処理ステータス管理」を行い、正常終了時
のみ次の処理をスタートさせる為、監視する必要がなく、大幅なユーザ
負担の軽減となります。
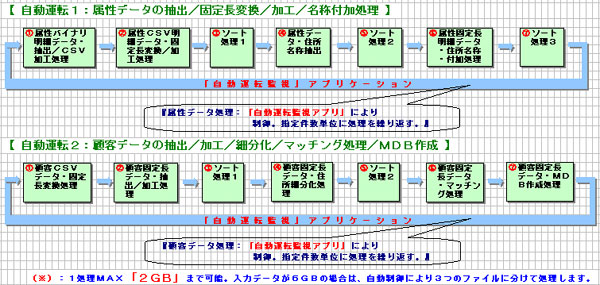
|

●マッチング処理により、顧客データへ地図座標情報が付加されたファイル
の形式は以下の3パターンを、GISへの提供ファイルとしています。
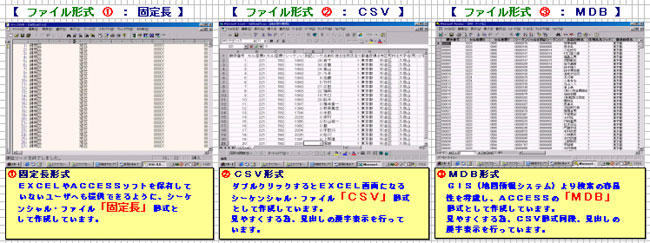
|

●顧客データへ座標情報を付加することにより、地図システムの活用が計れます。
|
|